Code overview
Most users will only interact with the command-line executable. In this document, we’ll give a brief overview of how these are used internally to help developers orient themselves with the project.
Python Modules
At the top-level, the bilby_pipe python package provides several
sub-modules as visualised here:

each submodule (e.g., bilby_pipe.utils) serves a different purpose.
On this page, we’ll give a short description of the general code structure.
Specific details for different modules can then be found by following the
links in the API reference section.
Workflow
The typical workflow for bilby_pipe is that a user calls the
bilby_pipe command line tool giving it some “User input”. Typically,
this is of the form of an ini file, and any extra command
line arguments. This user input is handled by the bilby_pipe.main
module (which provides the command-line interface). It generates two types of
output, “DAG files” and a “summary webpage” (if requested). I.e., the top-level
workflow looks like this:

Depending on the exact type of the job, the DAG may contain a number of jobs. Typically, there are generation and analysis jobs. For a simple job, e.g., analysing a GraceDB candidate. There may be one generation job (to load the JSON data from GraceDB, find relevant frame files and make PSDs) and one analysis job (to run some sampler given some prior etc.). For cases with multiple components (e.g., create an analysis n injections) things may be more complicated. The logic for handling all of this is contained within the main module.
In the most general case, there will be n parallel jobs with no inter-job dependencies. Within each of these jobs, there is typically a structure in the DAG as follows:
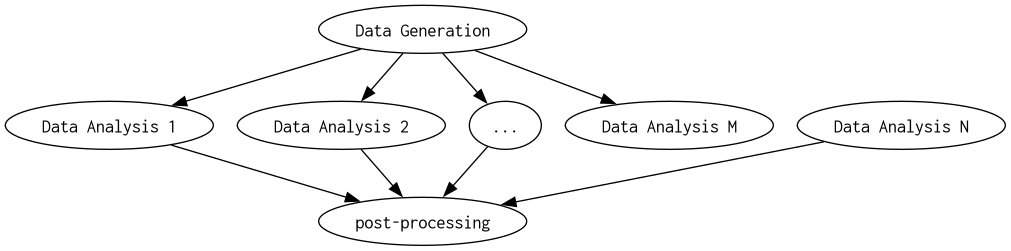
Each Data Analysis job refers to a different way to analyse the same data. For example, using different samplers, or different subsets of detectors. If there are M Data Anlaysis jobs and N top-level jobs, there is MN jobs in total.
The “Data Generation” job uses the bilby_pipe_generation executable to create all the data which may be analysed.
The “Data Analysis” jobs uses the bilby_pipe_analysis executable to create all the data which may be analysed.
For the case of running on GraceDB events, bilby_pipe has an additional step
to the typical workflow bilby_pipe_gracedb executable. For
this case the user can calls bilby_pipe_gracedb along with either the
GraceDB ID of the event or a json file containing information on the GraceDB
event. For examples on using bilby_pipe_gracedb please see the section
Running on GraceDB events under Examples.
See the table of contents below for an overview of the API.
Code Format
To ensure a consistent style across the project, bilby_pipe uses two
linting tools: flake8 and black. Practically speaking, when you submit a
merge request, these commands are run by the CI
$ black --check bilby_pipe/
$ flake8 .
which check a number of small stylistic and formatting issues. Often, you will find the CI fails due to difference between your style and those accepted by these commands. Usually these can be resolved by simply running
$ black bilby_pipe/
prior to committing (or run it, add the changes and add another commit). This
will reformat the code in the accepted style. To avoid having to do this, you
can use the pre-commit hook. To use this
feature, run the following commands from the bilby_pipe directory:
$ pip install pre-commit
$ pre-commit install
For a detailed discussion of why we use flake8 and black, you
be wish to read this article.