This short guide will illustrate how to estimate hyper-parameters from
posterior samples using bilby using a simplistic problem.
Setting up the problem
We are given three data sets labelled by a, b, and c. Each data set consists of
observations of a variable taken at a dependent variable
. Notationally, we can write these three data sets as where labels the
indexes of each data set.
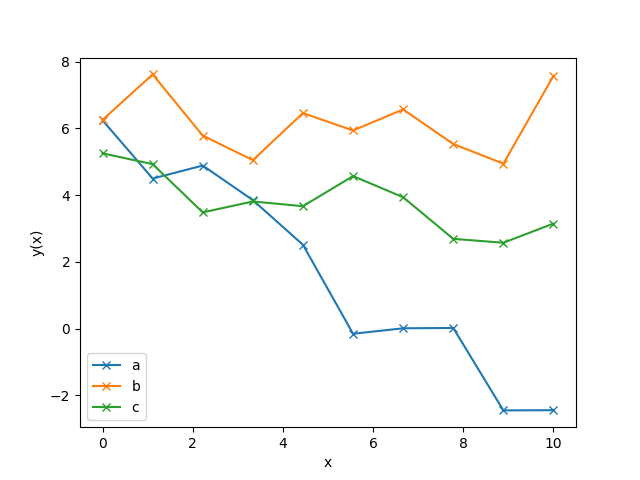
Plotting the data, we see that all three look like they could be modelled by
a linear function with some slope and some intercept:
Given any individual data set, you could write down a linear model and infer the intercept and gradient. For example, given the
a-data set, you could calculate by fitting the
model to the data. Here is a figure demonstrating the posteriors on the
intercept, for the three data sets given above
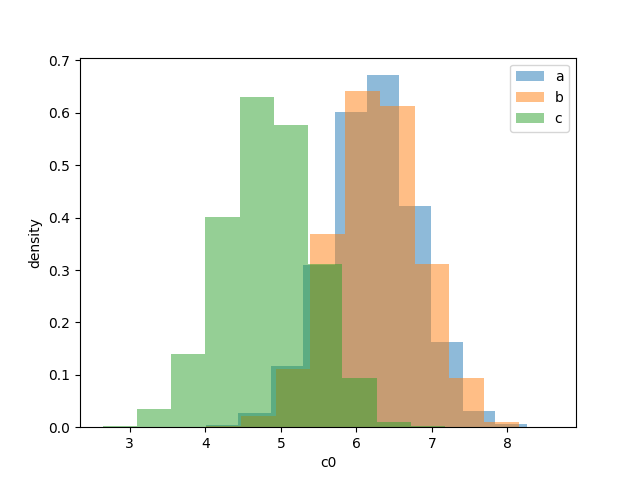
While the data looks noise, the overlap in the posteriors might
(especially given context about how the data was produced and the physical
setting) make you believe all data sets share a common intercept. How would
you go about estimating this? You could just take the mean of the means of the
posterior and that would give you a pretty good estimate. However, we’ll now
discuss how to do this with hyper parameters.
Understanding the population using hyperparameters
We first need to define our hyperparameterized model. In this case, it is
as simple as
That is, we model the population (from which each of the data sets
was drawn) as coming from a normal distribution with some mean and some
standard deviation.
To do - write in details of the likelihood and its derivation
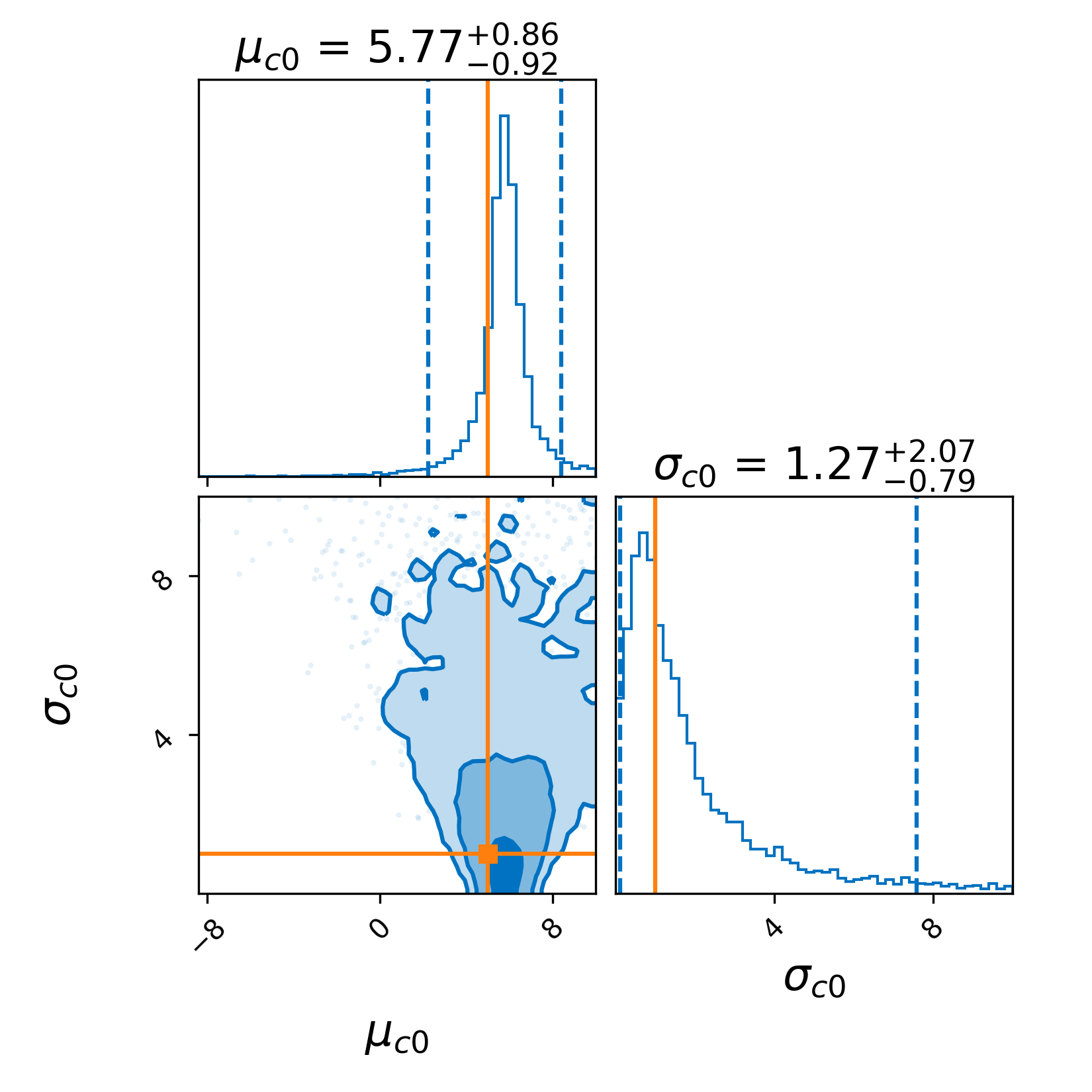
For the samples in the figure above, the posterior on these hyperparamters
is given by